The notes of Text2Scene: Generating Compositional Scenes from Textual Descriptions
Overview
Unlike the previous work, this paper doesn’t adopt Generative adversarial network, but a combination of encoder-decoder architecture with a semi-parametric retrieval-based approach TOREAD. Under minor modification, this model performs decent generation of different forms of scene representation, including clip-art generation on Abstract Scenes, semantic layout on COCO and compositional image generation on COCO.
Preliminaries
Difficulties encountered
Generating rich textual representation has two main challenges, one is indirect hint at the presense of attributes from input textual description (e.g. “Mike is surprised” should change facial attributes on the generated object “Mike”), and another is relative spatial configurations within the text (e.g. “Mike is runing towards to his girlfriend” confines the orientation of “Mike” dependent on “his girlfriend”)
Related work
Relative work is as follows:
-
Semi-parametric Image Synthesis proposed a retrieval-based semi-parametric method for image synthesis given an input by a human. But different from the previous work using ground-truth semantic layout as input, this work learns to predict the location and layout of the object indirectly from the text.
-
Image generation from scene graphs, it proposed a graph-convolution model to generate from structured scene graph where objects and their relationship are provided as inputs, while this work the presence of objects is inferred from text.
-
Inferring semantic layout for hierarchical text-to-image synthesis generates the layout as the intermediate representations in separably trained modules, but this work generate pixel-wise outputs with semi-parametric retrieval module without advesarial training.
-
Visual dialog for collaborative drawing performs pictorial generation from chat logs, compared to out works that need text much considerably more underspecified.
Network structure
Using a sequence-to-sequence approach, this model arranges the generated object sequentially along with their attributes (locations, sizes, aspect ratios, pose, appearance and more) on an initially empty canvas.
Generally, Text2Scene model consists of
- a text encoder that maps input sentence to a set of embedding representations
- an object decoder that predicts the next generated object conditioned on the current scene state
- an attribute decoder that determines the attribute of the next object
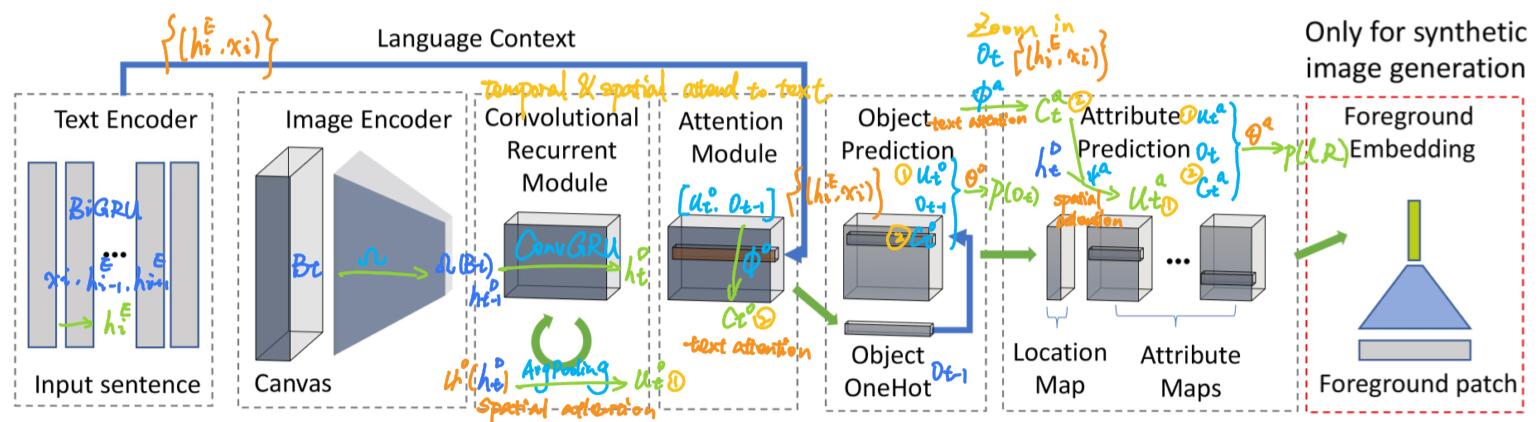
Text encoder
To compute for each word $i$ given input text
\[h_{i}^{E}=\operatorname{BiGRU}\left(x_{i}, h_{i-1}^{E}, h_{i+1}^{E}\right)\]here BIGRU is a bidirectional GRU cell, $ x_{i} $ is a word embedding and $h_{i}^{E}$ is a vector encoding the current word and its context.
Image encoder and recurrent module
To use a convolutional network $\Omega$ to encode current canvas ${B}_{t}$ into a $\mathcal{C} \times H \times W$ feature map representing the current scene state, and to model the history of the scene state $ \left\{ h_{t}^{D} \right\} $ by a convolutional GRU. $ h_{t}^{D}$ is an important representation of both temporal and spatial dynamical information.
\[h_{t}^{D}=\operatorname{ConvGRU}\left(\Omega\left(B_{t}\right), h_{t-1}^{D}\right)\]In case that $h_{t}^{D}$ fails to capture small objects, previous step $ {o}_{t-1} $ is provided as input to the downstream decoders.
Attention-based object decoder
The object decoder based on attention mechanism outputs the likelihhod score on all objects in object vocabulary library $\mathcal{V}$, and takes as input:
- the current scene state $ \left\{ h_{t}^{D} \right\} $
- the text features $ \left\{\left(h_{i}^{E}, x_{i}\right)\right\} $
- the preiviously predicted object $ o_{t-1} $
Spatial attention convolutional network
where $\Psi$ is a convolutional network with spatial attention on $ \left\{ h_{t}^{D} \right\} $ to collect spatial contexts for the object prediction, e.g. what objects have already been added. Then by average pooling layer, the attended features are fused into a vector $u_{t}^{o}$.
\[u_{t}^{o}=\text { AvgPooling }\left(\Psi^{o}\left(h_{t}^{D}\right)\right)\]Text-based attention module
Text-based attention module $\Phi$ uses $u_{t}^{o}$ to attend to the text features $ \left\{\left(h_{i}^{E}, x_{i}\right)\right\} $, and encodes the knowledge of all described objects having been added to the scene thus far ideally.
\[c_{t}^{o}=\Phi^{o}\left(\left[u_{t}^{o} ; o_{t-1}\right],\left\{\left(h_{i}^{E}, x_{i}\right)\right\}\right)\]Likelihood predicting perceptrons
$\Theta^{o}$ is two-layers perceptrons to predict the likelihhod of the next object $p\left(o_{t}\right)$ using a softmax function.
\[p\left(o_{t}\right) \propto \Theta^{o}\left(\left[u_{t}^{o} ; o_{t-1} ; c_{t}^{o}\right]\right)\]Attention-based attribute decoder
For each spatial location in $h_{t}^{D}$, This part predicts both location likelihood $ \left\{l_{t}^{i}\right\}_{i=1 \ldots N} $ and attribute likelihoods $\left\{R_{t}^{k}\right\}$ to the object $o_{t}$. Here possible locations are discretized into the same resolution of $h_{t}^{D}$. TOREAD
“Zoom in” module
$\Phi^{a}$ is to zoom in the language context of $o_{t}$ by attending to the input text feature.
\[{c_{t}^{a}=\Phi^{a}\left(o_{t},\left\{\left(h_{i}^{E}, x_{i}\right)\right\}\right)}\]Location prediction convolution network
Compared to $c_{t}^{o}$ which contain information of objects that have not been added yet, $c_{t}^{a}$ focuses more specifically on contents realted to the current object $o_{t}$.
\[{u_{t}^{a}=\Psi^{a}\left(\left[h_{t}^{D} ; c_{t}^{a}\right]\right)}\]Then $\Psi^{a}$, a CNN spatially attending to $h_{t}^{D}$, is to find an affordable location to append $o_{t}$.
Likelihood predicting convolutional network
$\Theta^{a}$ is implemented by a convolutional network with softmax classifiers over each value of $l_{t}$ and the discrete $R_{t}^{k}$.
\[{p\left(l_{t},\left\{R_{t}^{k}\right\}\right)=\Theta^{a}\left(\left[u_{t}^{a} ; o_{t} ; c_{t}^{a}\right]\right)}\]Foreground patch embedding
For the third mission to generate images composed of patches retrieved from others, a particular $Q_{t}$ is proposed to predict every location in the output feature map but is used at test time to retrieve similar patches from pre-computed collection of object segments from other images TOREAD. A patch embedding network using a CNN reduces the foreground patch of target image into a 1D vector $F_{t}$. To minimize the $\ell_{2}$-distance between $Q_{t}$ and $F_{t}$, it uses the triplet embedding loss ($P^\text {color}$, $P^\text {mask}$, $P^\text {context}$) to minimize the distance of $\left\|Q_{t}, F_{t}\right\|_{2}$ and maximize the distance of $\left\|Q_{t}, F_{k}\right\|_{2}$. Here $F_{k}$ is the feature of a negative patch randonly selected from the same category of $F_{t}$. TOREAD
\[L_{\text {triplet}}\left(Q_{t}, F_{t}\right)=\max \left\{\left\|Q_{t}, F_{t}\right\|_{2}-\left\|Q_{t}, F_{k}\right\|_{2}+\alpha, 0\right\}\]where $\alpha$ is a margin hyper-parameter.
Objective
The loss function with reference values $\left(O_{t}, l_{t},\left\{R_{t}^{k}\right\}, F_{t}\right)$ is:
\[L= -w_{o} \sum_{t} \log p\left(o_{t}\right)-w_{l} \sum_{t} \log p\left(l_{t}\right) -\sum_{k} w_{k} \sum_{t} \log p\left(R_{t}^{k}\right)\\ +w_{e} \sum_{t} L_{t r i p l e t}\left(Q_{t}, F_{t}\right) +w_{a}^{O} L_{a t t n}^{O}+w_{a}^{A} L_{a t t n}^{A}\]where $L_{a t t n}^{*}$ are regularization terms inspired by the doubly stochastic attention module propose in section 4.2.1 of Show, attend and tell: Neural image caption generation with visual attention and $w$ are hyper-parameters controlling the relative contribution of each loss.
Conclusion
Text2Scene model demonstrates the capacity on both abstract and real images, which opens the possibility for future work on transfer learning across domains.